大数据导论
大数据:指无法在一定时间范围内使用常规软件工具进行捕捉,管理和处理的数据集合。 大数据主要解决海量数据的采集,存储和分析计算问题
存储单位:bit, Byte, KB, MB, GB, TB, PB, EB, ZB, YB, BB, NB, DB
大数据特点
*Volumn(大量) Velocity(高速) Variety(多样) Value(低价值密度)
Hadoop概述
hadoop是什么
hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题。广义来说,Hadoop通常指的是一个更广泛的概念——Hadoop生态圈
hadoop发展历史
创始人Doug Cutting,在Lucene框架基础上进行优化升级
hadoop优势
*高可靠性 高扩展性 高效性 高容错性
hadoop组成
hadoop1.x,2.x,3.x区别 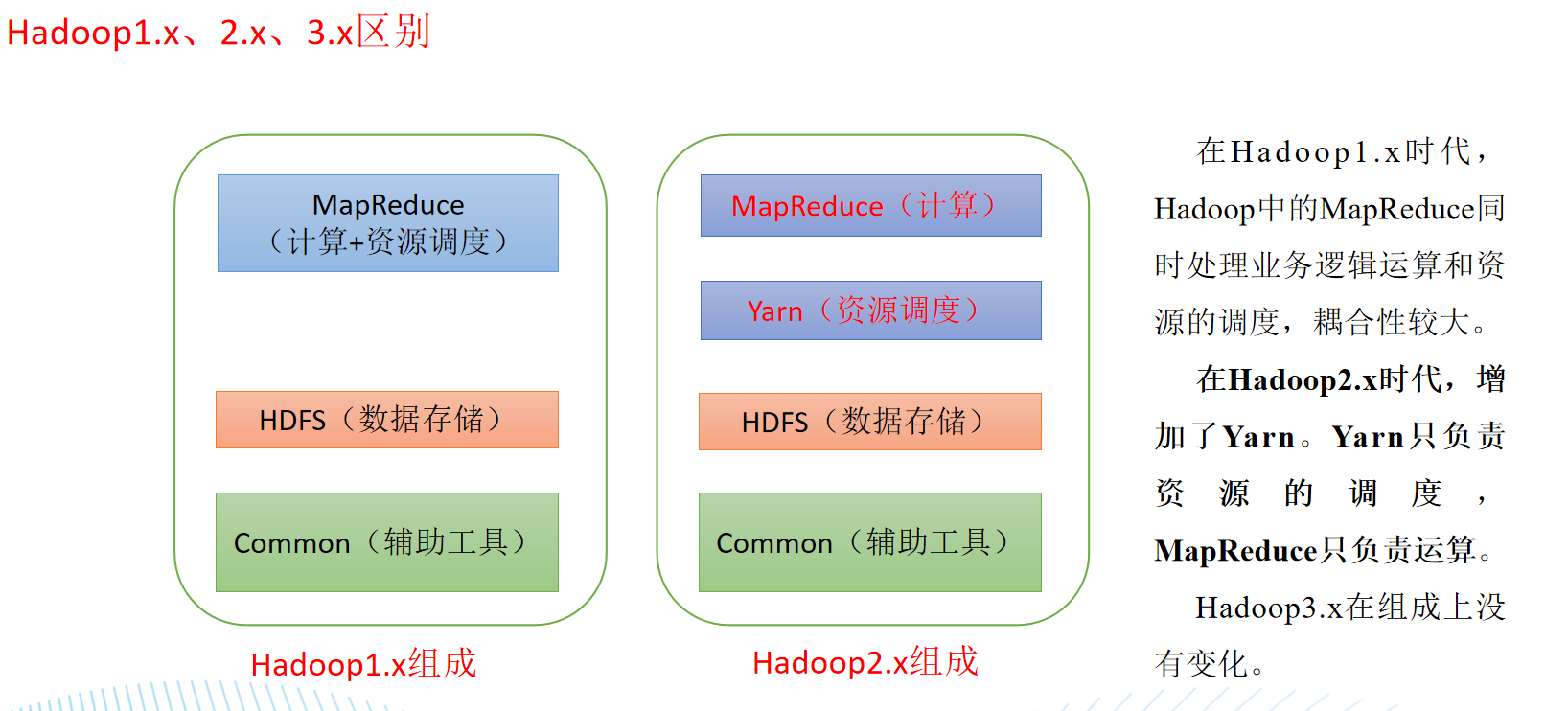
HDFS
HDFS是一个分布式文件系统
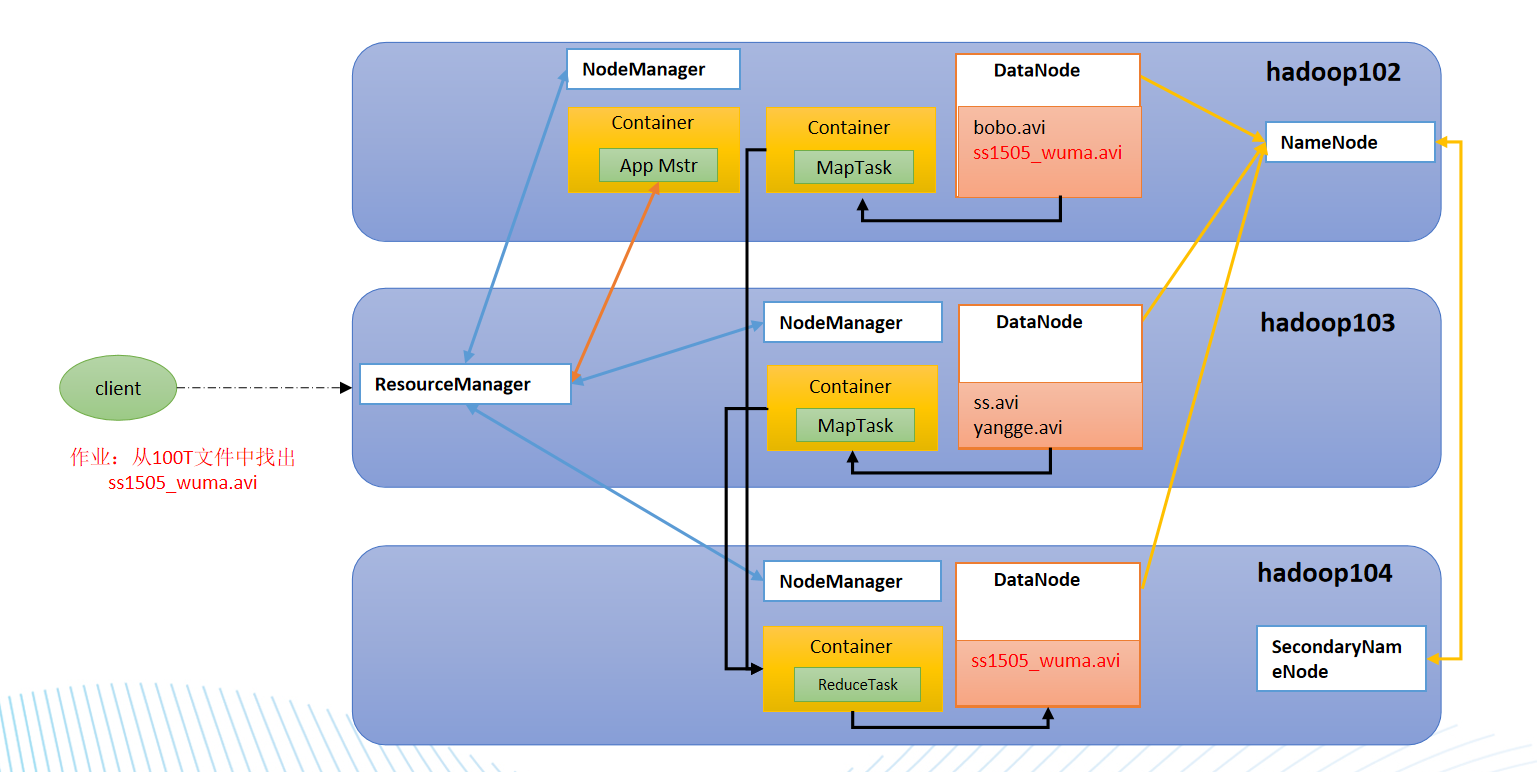
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性,以及每个文件的块列表和块所在的DataNode等
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和
- SecondaryNameNode(2nn):每隔一段时间对NameNode元数据备份
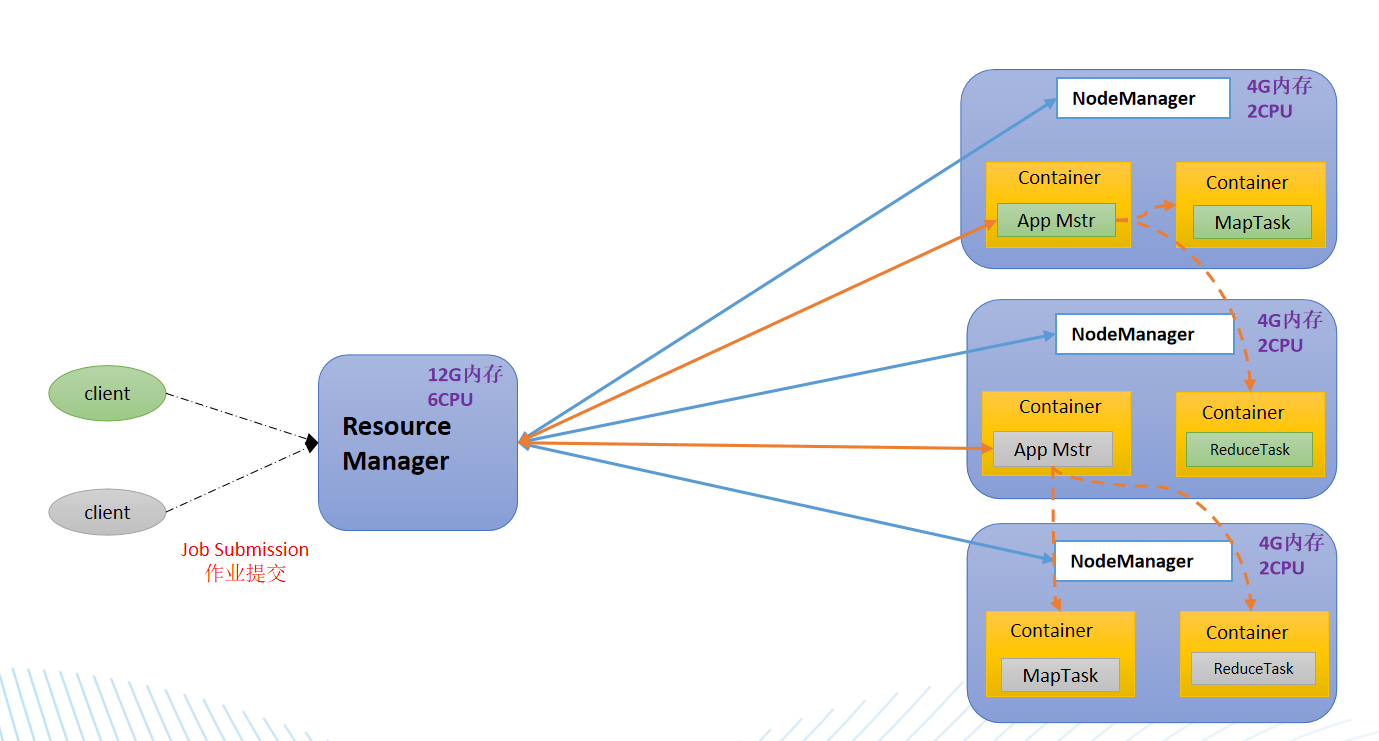
YARN
Yarn是另一种资源协调者,是Hadoop的资源管理器
- ResourceManager(RM):整个集群资源(内存,cpu等)的老大
- NodeManager(NM):单个节点服务器资源老大
- ApplicationMaster(AM):单个任务运行的老大
- Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存,cpu,磁盘,网络等 ps: 客户端可以有多个 集群上可以运行多个ApplicationMaster 每个NodeManager上可以有多个Container
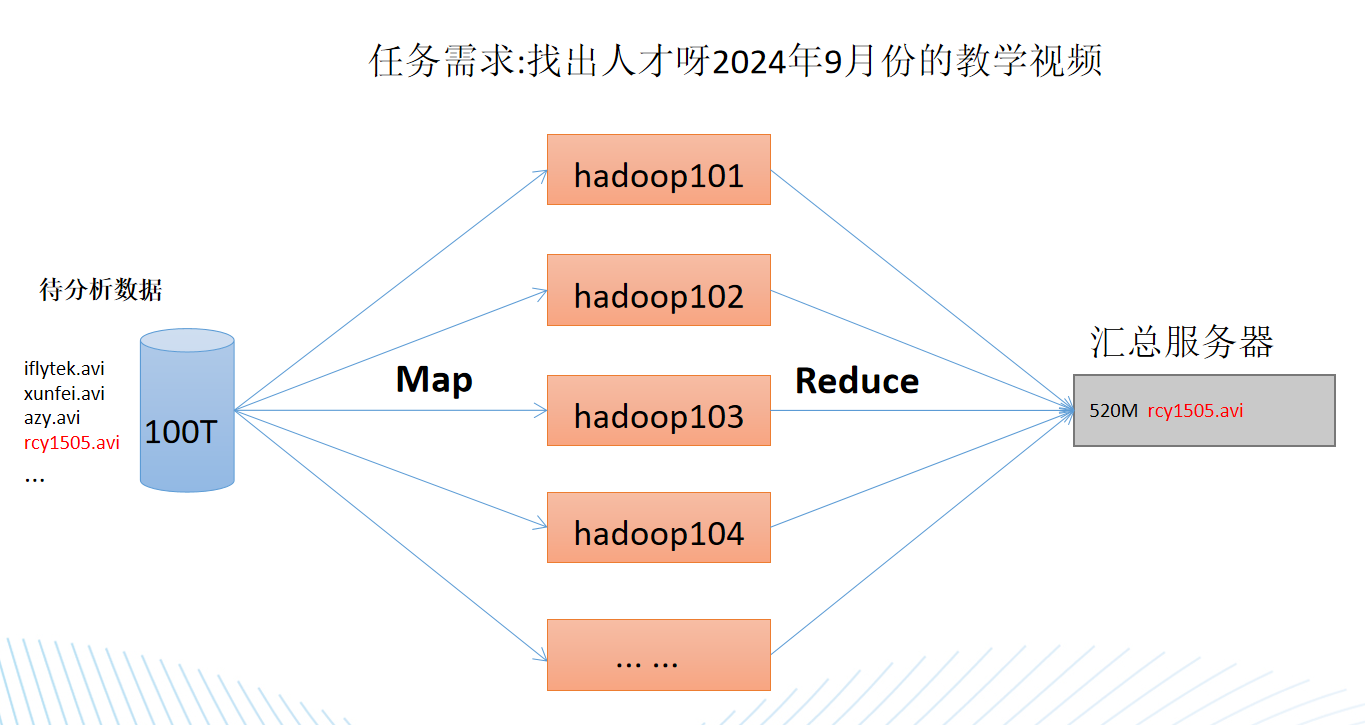
MapReduce
计算部分被分为两个阶段:Map和Reduce Map阶段并行处理输入数据 Reduce阶段对Map结果进行汇总
三者关系
HDFS
分布式存储层 将大文件分割成块,分散存储在多态机器上提供高容错性和高吞吐量的数据访问 HDFS是Yarn和MapReduce的数据基础,存储待处理的输入数据和计算结果
Yarn
资源管理和任务调度层 负责集群的资源分配(cpu,内容)和任务调度(如MapReduce,Spark等),通过ResourceManager和NodeManager协调资源 Yarn是MapReduce的运行平台:MapReduce作业通过Yarn申请资源并执行。解耦了Hadoop的存储(HDFS)与计算(MapReduce),是Hadoop可以支持多种计算框架(如Spark,Flink)
MapReduce
分布式计算模型 提供简单的编程模型(Map和Reduce阶段),处理HDFS上的海量数据。自动并行化计算,处理数据分片(Split),排序(Shuffle),聚合等 依赖HDFS:输入和输出数据存储在HDFS上。 依赖Yarn:由Yarn分配资源并调度MapReduce的任务(如Map Task和Reduce Task)
协作流程(以WorkCount为例)
1.数据存储:文本文件存入HDFS,被拆分为多个块分布在不同节点。 2.资源申请:提交MapReduce作业到Yarn,Yarn的ResourceManager分配容器(Container)运行任务 3.计算执行:
- Map阶段:多个Map Task并行处理HDFS的数据块,生成键值对
- Shuffle & Reduce阶段:Yarn调度Reduce Task聚合结果,最终输出到HDFS。
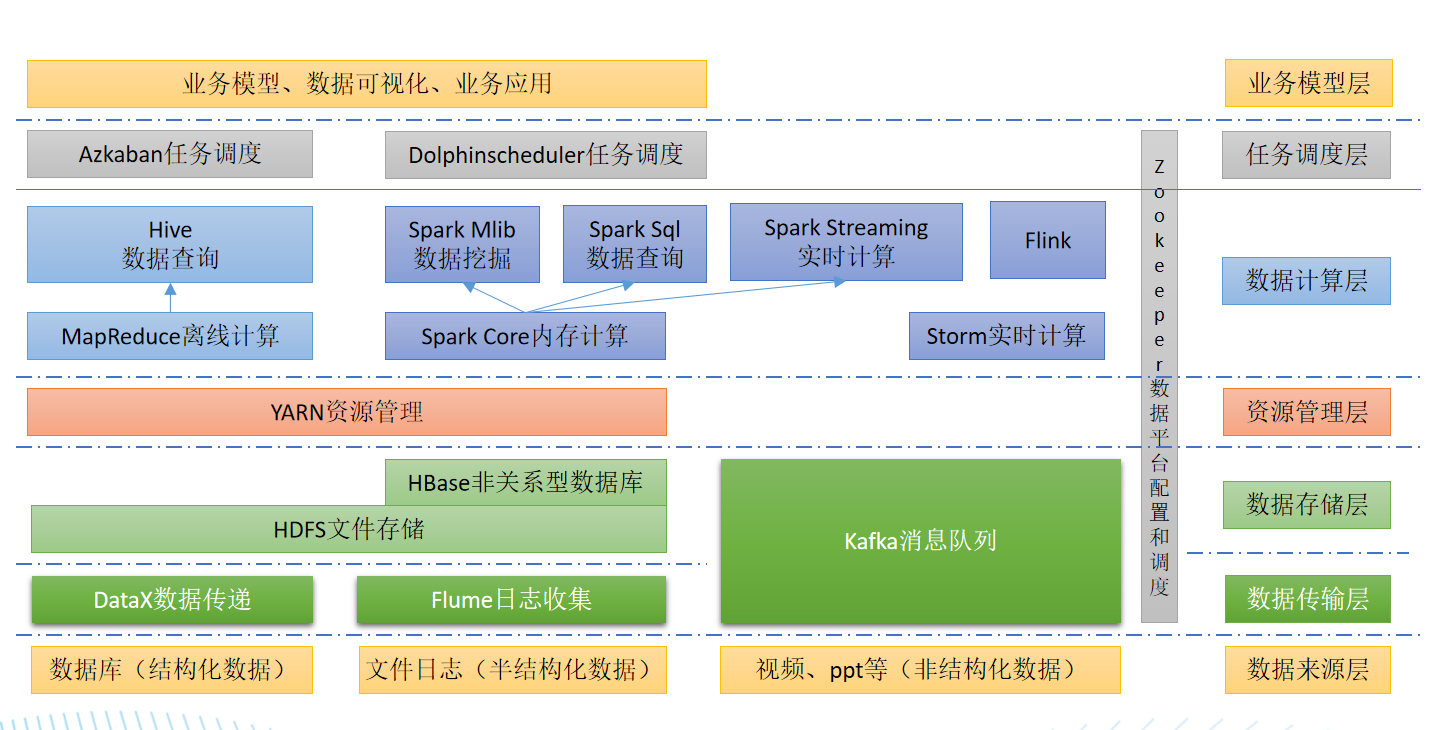
技术生态体系